
Filter模式
Java的IO标准库提供的InputStream根据来源可以包括:
- FileInputStream:从文件读取数据,是最终数据源;
- ServletInputStream:从HTTP请求读取数据,是最终数据源;
- Socket.getInputStream():从TCP连接读取数据,是最终数据源;
- ...
如果我们要给FileInputStream添加缓冲功能,则可以从FileInputStream派生一个类:
BufferedFileInputStream extends FileInputStream {}如果要给FileInputStream添加计算签名的功能,类似的,也可以从FileInputStream派生一个类:
DigestFileInputStream extends FileInputStream {}如果要给FileInputStream添加加密/解密功能,还是可以从FileInputStream派生一个类:
CipherFileInputStream extends FileInputStream {}如果要给FileInputStream添加缓冲和签名的功能,那么我们还需要派生BufferedDigestFileInputStream。如果要给FileInputStream添加缓冲和加解密的功能,则需要派生BufferedCipherFileInputStream。
我们发现,给FileInputStream添加3种功能,至少需要3个子类。这3种功能的组合,又需要更多的子类: 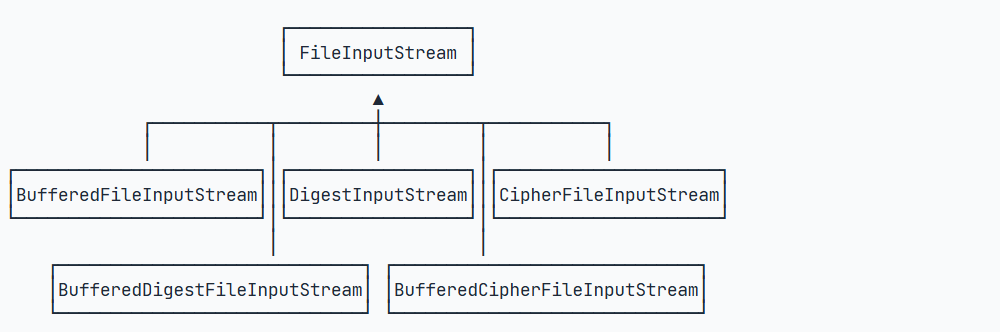 这还只是针对FileInputStream设计,如果针对另一种InputStream设计,很快会出现子类爆炸的情况。
这还只是针对FileInputStream设计,如果针对另一种InputStream设计,很快会出现子类爆炸的情况。
因此,直接使用继承,为各种InputStream附加更多的功能,根本无法控制代码的复杂度,很快就会失控。
为了解决依赖继承会导致子类数量失控的问题,JDK首先将InputStream分为两大类:
一类是直接提供数据的基础InputStream,例如:
- FileInputStream
- ByteArrayInputStream
- ServletInputStream
- ...
一类是提供额外附加功能的InputStream,例如:
- BufferedInputStream
- DigestInputStream
- CipherInputStream
- ...
当我们需要给一个“基础”InputStream附加各种功能时,我们先确定这个能提供数据源的InputStream,因为我们需要的数据总得来自某个地方,例如,FileInputStream,数据来源自文件:
InputStream file = new FileInputStream("test.gz");紧接着,我们希望FileInputStream能提供缓冲的功能来提高读取的效率,因此我们用BufferedInputStream包装这个InputStream,得到的包装类型是BufferedInputStream,但它仍然被视为一个InputStream:
InputStream buffered = new BufferedInputStream(file);最后,假设该文件已经用gzip压缩了,我们希望直接读取解压缩的内容,就可以再包装一个GZIPInputStream:
InputStream gzip = new GZIPInputStream(buffered);无论我们包装多少次,得到的对象始终是InputStream,我们直接用InputStream来引用它,就可以正常读取:  上述这种通过一个“基础”组件再叠加各种“附加”功能组件的模式,称之为Filter模式(或者装饰器模式:Decorator)。它可以让我们通过少量的类来实现各种功能的组合:
上述这种通过一个“基础”组件再叠加各种“附加”功能组件的模式,称之为Filter模式(或者装饰器模式:Decorator)。它可以让我们通过少量的类来实现各种功能的组合: 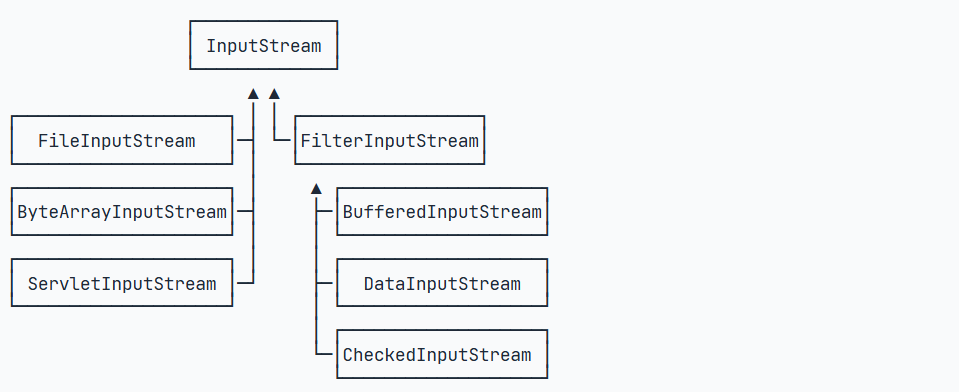 类似的,OutputStream也是以这种模式来提供各种功能:
类似的,OutputStream也是以这种模式来提供各种功能: 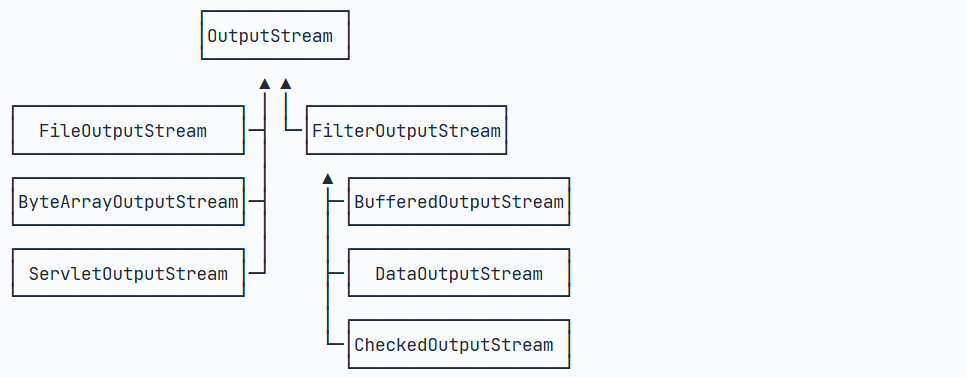
编写FilterInputStream
我们也可以自己编写FilterInputStream,以便可以把自己的FilterInputStream“叠加”到任何一个InputStream中。
下面的例子演示了如何编写一个CountInputStream,它的作用是对输入的字节进行计数:
import java.io.*;
public class Main {
public static void main(String[] args) throws IOException {
byte[] data = "hello, world!".getBytes("UTF-8");
try (CountInputStream input = new CountInputStream(new ByteArrayInputStream(data))) {
int n;
while ((n = input.read()) != -1) {
System.out.println((char)n);
}
System.out.println("Total read " + input.getBytesRead() + " bytes");
}
}
}
class CountInputStream extends FilterInputStream {
private int count = 0;
CountInputStream(InputStream in) {
super(in);
}
public int getBytesRead() {
return this.count;
}
public int read() throws IOException {
int n = in.read();
if (n != -1) {
this.count ++;
}
return n;
}
public int read(byte[] b, int off, int len) throws IOException {
int n = in.read(b, off, len);
if (n != -1) {
this.count += n;
}
return n;
}
}注意到在叠加多个FilterInputStream,我们只需要持有最外层的InputStream,并且,当最外层的InputStream关闭时(在try(resource)块的结束处自动关闭),内层的InputStream的close()方法也会被自动调用,并最终调用到最核心的“基础”InputStream,因此不存在资源泄露。
小结
Java的IO标准库使用Filter模式为InputStream和OutputStream增加功能:
- 可以把一个InputStream和任意个FilterInputStream组合;
- 可以把一个OutputStream和任意个FilterOutputStream组合。
Filter模式可以在运行期动态增加功能(又称Decorator模式)。